O código Maple para o caso m = 3 é mostrado abaixo:
##############################
DeltaP := m -> (Pm - P1)/m;
Pressures := m -> local i; [seq(P1 + (i - 1.0)*DeltaP(m), i = 1 .. m + 1)];
P1 := Pini;
P1 := 5
P4 := Pfin;
Pm := Pfin;
P2 := Pressures(3)[2];
P2 := 16.66666667
P3 := Pressures(3)[3];
P3 := 28.33333333
Pressures(3);
[5., 16.66666667, 28.33333333, 40.00000000]
##############################
U1 := rhs(h(P1)[1]);
U1 := 9.625556118
U2 := rhs(h(P2)[1]);
U2 := 2.727090188
U3 := rhs(h(P3)[1]);
U3 := 1.498478902
U4 := rhs(h(P3)[1]);
U4 := 1.498478902
##############################
hu1 := solve({U1 = P1*ak1 + bk1, U2 = P2*ak1 + bk1}, {ak1, bk1});
hu1 := {ak1 = -0.5912970795, bk1 = 12.58204152}
hu2 := solve({U2 = P2*ak2 + bk2, U3 = P3*ak2 + bk2}, {ak2, bk2});
hu2 := {ak2 = -0.1053095389, bk2 = 4.482249169}
hu3 := solve({U3 = P3*ak3 + bk3, U4 = P4*ak3 + bk3}, {ak3, bk3});
hu3 := {ak3 = 0., bk3 = 1.498478902}
##############################
ak1 := (U1 - U2)/(P1 - P2);
ak1 := -0.5912970795
bk1 := (P1*U2 - P2*U1)/(P1 - P2);
bk1 := 12.58204152
ak2 := (U2 - U3)/(P2 - P3);
ak2 := -0.1053095389
bk2 := (P2*U3 - P3*U2)/(P2 - P3);
bk2 := 4.482249170
ak3 := (U3 - U4)/(P3 - P4);
ak3 := -0.
bk3 := (P3*U4 - P4*U3)/(P3 - P4);
bk3 := 1.498478902
##############################
U := P -> piecewise(P1 <= P and P <= P2, ak1*P + bk1, P2 <= P and P <= P3, ak2*P + bk2, P3 <= P and P <= P4, ak3*P + bk3);
Explicação:
- Cálculo dos coeficientes ak e bk: Cada intervalo [Pk, Pk+1] é descrito por uma função linear da forma U(P)= ak P + bk, onde os coeficientes são calculados a partir dos valores de P e U nas extremidades do intervalo considerado.
- Estrutura piecewise para U(P): A função é definida como uma piecewise, com diferentes expressões para U(P)) em cada subintervalo de P.
- Adaptação para m=3: Nesse caso, temos três subintervalos [P1,P2], [P2,P3] e [P3,P4]. O código reflete essa divisão, ajustando ak e bk para cada intervalo.
Observação:
Certifique-se de que os valores de P1, P2, P3, P4 e U1, U2, U3, U4 sejam fornecidos previamente, como no caso de m=2.
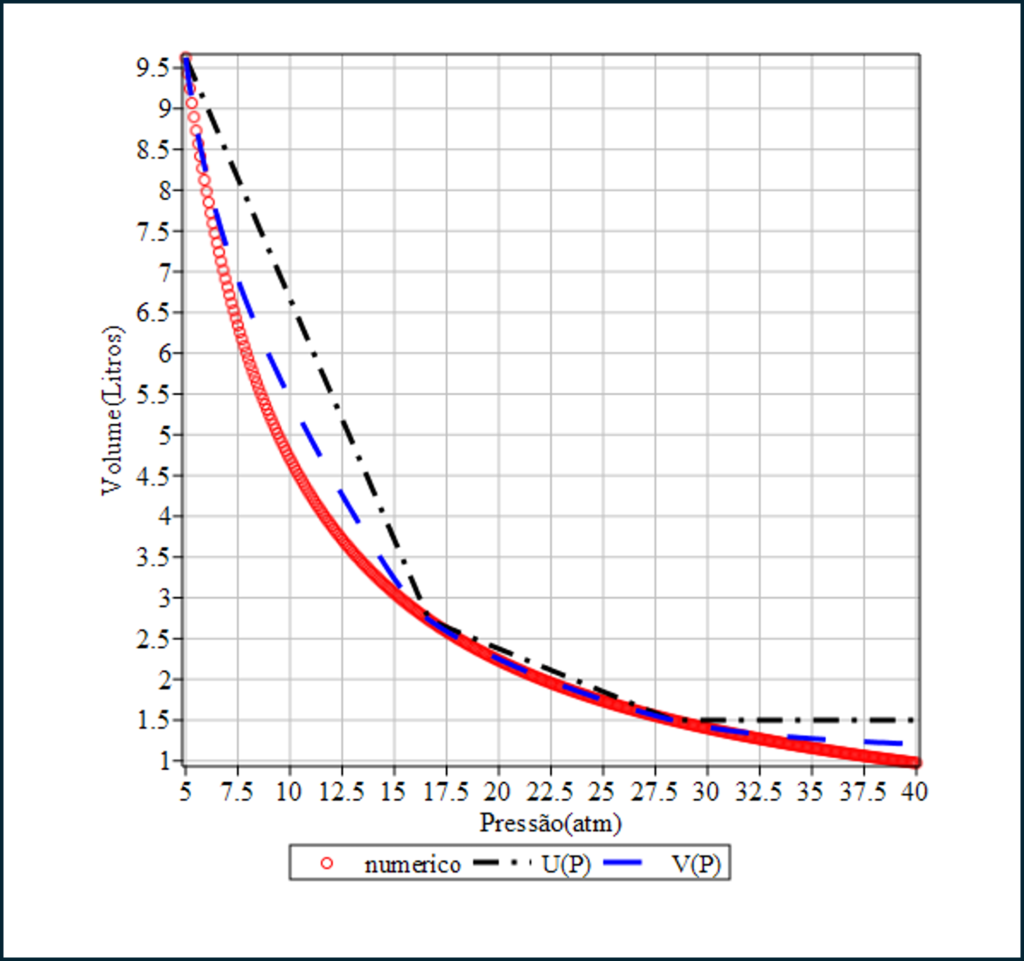
O gráfico agora
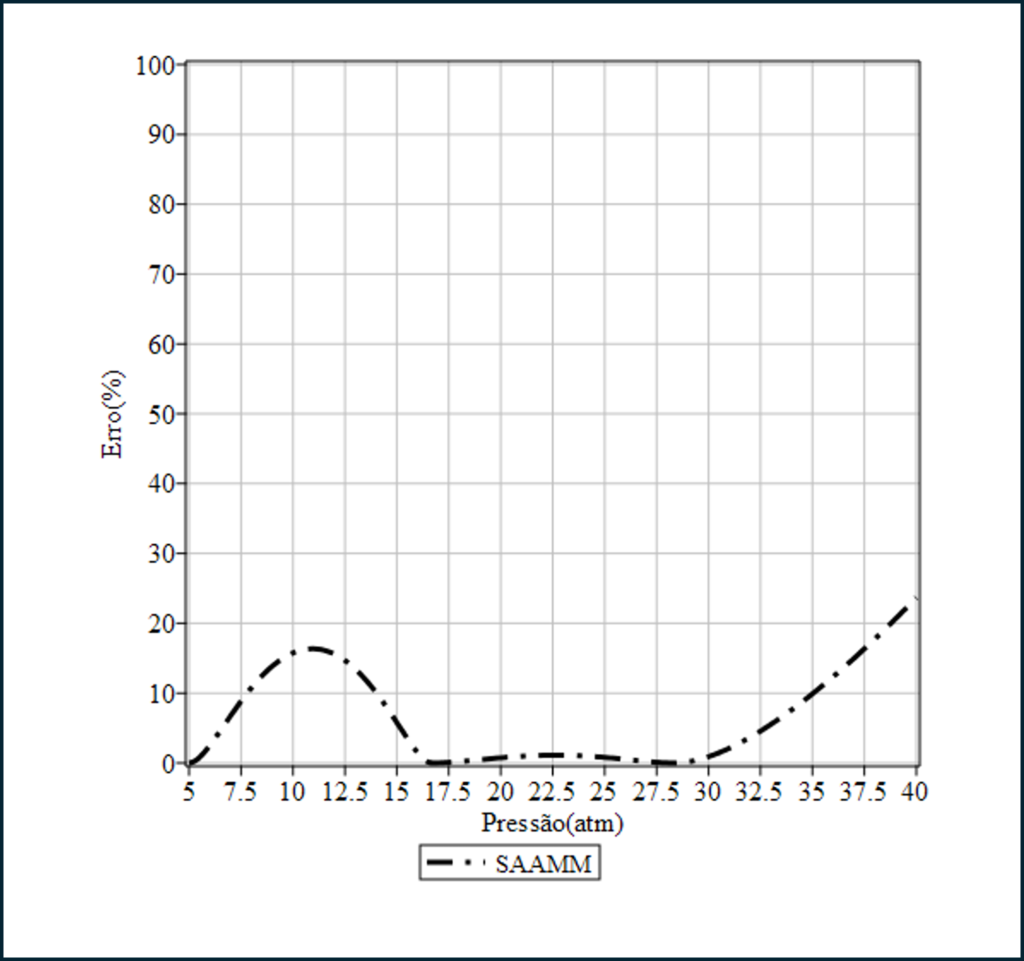
O erro relativo é apresentado abaixo
A partir desse estudo podemos facilmente construir uma generalização para m. (…->)
- Para m=1: Linearização única no intervalo inteiro, maior erro. (…->)
- Para m=2: Melhor aproximação com dois segmentos. (…->)
- Para m=3: Refinamento ainda maior, com possibilidades de erro relativo no resultado final, significativamente reduzido. (…->)
- Assim por diante. Generalização para m. (…->)
- Generalização para m com ajuste parabólico. (…->)